

How to Build Safe AI (Without Making the AI Safe)
Lessons from aviation, manufacturing, and the 16-year-old driver


As agentic LLMs are widely deployed to assist with all sorts of tasks, it is critical to make sure they are as safe as a Boeing 747.

Existing approaches focus on how to provide safety guarantees for the LLM itself, but this task is challenging and perhaps impossible. Think of an LLM as a lens. Depending on the direction, phase, and wavelength of the incoming light, it refracts differently. Like a viroid, and LLM is a consciousoid, and how it behaves depends on the light hitting it: the high-dimensional input from its interlocutor. We do not yet have a closed-form model for this projection, so determining whether a given input produces a given output requires running an empirical test. The LLM’s high-dimensional input space, output space, and parameter space make it fundamentally hard to certify.
Instead, I propose a systems approach: treat the LLM as one component of a larger system. The LLM itself can never be safe, and in fact, we do not trust it at all. But the system it is part of can have safety guarantees by following practices in ISO standards for safety, security, and risk. These same practices enable us to have airplanes in the sky, cars on the road, and robots in factories.
The methodology is straightforward: safety-rated guardrails at the input/output boundaries of the system ensure safe operation. To be verifiable, say, to a one-in-100,000 probability of failure, as specified in ISO 61508, these guardrails must be low-dimensional relative to the LLM. For example, a safety-rated E-stop in a factory robot must promise with 10^-5 that it will actually stop the robot if depressed in order to be certified by TÜV. A simple example: a check that the system cannot write outside of a specified directory. As dimensionality increases, guardrails may become probabilistic, for example, a classifier with a probabilistic guarantee could validate a bash script before it executes.
The highest-dimensional and noisiest channel of all is the channel between the human and the LLM. Prompted by the LLM, the human could go off and do, well, anything, including quite horrible things. It is therefore not possible to have ISO-style safety guarantees around the human-LLM interaction. A more realistic way to think about this is to compare human-LLM interaction to human-human interaction, which has a wide spectrum. We tolerate this sort of risk in our society: cult leaders, abusers, and scammers exist and are sometimes successful. To combat this risk, we use a combination of interventions that maintain our societal structures: law, health care, education, and more. We use this approach today when we put a 16-year-old driver behind the wheel. The car itself is constructed and certified according to these safety standards. The 16-year-old is not, so we educate them, we make them have a teacher in the car, and eventually we let them drive. (And we tolerate car accidents as the leading cause of death in that age group).
Here is where the analogy to humans starts to break. The residual risk society tolerates from scammers and cult leaders is calibrated to human time constants. A scammer takes days or weeks to build trust with one victim. Our interventions, law, education, and social institutions evolved against that clock. LLMs run the same loop in seconds, in parallel, across millions of targets, exploiting the very mechanisms humanity has based its structures around. To name this precisely, consider the total societal harm from a class of agents:
Rtotal=Nrp(1-v)
Where N is the number of deployed agents, r is interactions per unit time per agent, p is the probability of a harmful outcome per interaction, and v is the verification coverage of our guardrails. For humans, N × r is bounded by population and biology. For LLMs, N × r is bounded instead by the inference throughput of available data centers, the bandwidth of the internet, and the context window that the model can be provided. Those bounds are rising fast, and none of them shares a ceiling with human biology. Even if p is lower for an LLM than for a skilled human scammer, Rtotal can exceed what our existing interventions were calibrated to absorb.
This is where LLM speed, the thing that creates the problem, also points toward the solution. Two things scale with the time budget per interaction: utility to the user, which falls as interactions get slower, and verification coverage, which rises as we get more time to check outputs. Model them as:
U(t)=e-t, v(t)=1-e-kt
Where α is how much users lose per unit of added latency, and k is the verification efficiency. Net value per interaction is:
V(t)=U(t)v(t)=e-t(1-e-kt)
Maximizing V gives an optimal time budget:
t =(1/k)(1+k/)
This equation has the shape of a classic speed-accuracy tradeoff. The (1 − e^(−kt)) term is Wickelgren’s function from 1977, and the optimization of deliberation time against decaying utility has been solved in drift-diffusion models, in neuroscience, and in economics. The math is not new. The reframing is: k is the efficiency of a parallel verifier, not an individual’s evidence accumulation, and α is society’s aggregate latency tolerance, not personal opportunity cost. The tradeoff psychology studied one decision at a time reappears as an engineering problem at the datacenter scale.
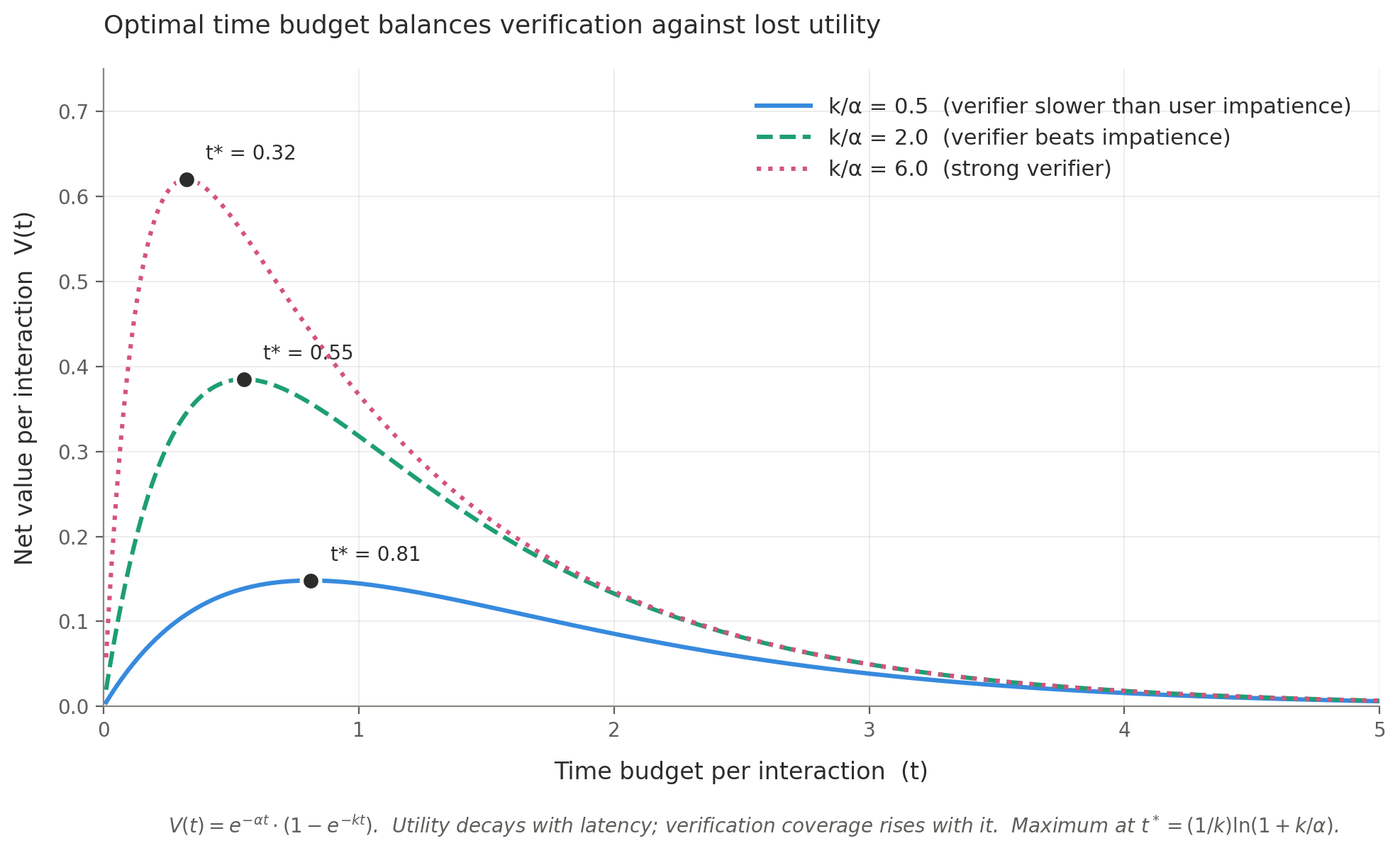
The ratio k/α is what determines whether slowing down is worth it. When k ≪ α, verifiers are too slow to matter, and the system should just optimize for speed. When k ≫ α, verifiers can do real work in the time budget, and the optimum shifts toward more verification. Humans cannot exploit this tradeoff because we do not have concurrent processes running checks on our own cognition at millisecond latency. LLMs can. While one process drafts an output, another simulates consequences, validates against policy, or cross-checks with a second model. Better verifiers, meaning higher k relative to α, raise the peak and shift it earlier: safety and throughput improve together. The old interventions assumed a serial agent with no spare cycles. LLMs are not that kind of agent.
This math means the systems-safety playbook applies, and it needs to be extended. We still want safety-rated guardrails at system boundaries, the way we do for factory robots and aircraft. We also need a new category of intervention that exploits the latency budget LLM speed creates, and that treats verification coverage as a first-class engineering target rather than an afterthought.
For LLMs, we need to develop these interventions while also understanding that no intervention can make an LLM, on its own, safe enough for an airplane cockpit. In my introduction to robotics course, I ask my students to read an FAA crash report about the 2009 Hudson River mid-air collision between a helicopter and a small airplane. One contributing factor to the crash was that the FAA controller was engaged in a “non-pertinent phone call,” and failed to correct the pilot’s incorrect readback of the Newark control tower’s radio frequency. But this sort of accident is rare exactly because we have many checkpoints, because we recognize that humans themselves are untrustworthy and need layers of verification.
We know how to build safe systems around untrustworthy components. We’ve been doing it for decades in aviation, medicine, and manufacturing. The lessons apply to AI, but they are not sufficient for AI. The untrustworthy components we have now run faster than the interventions we built for the untrustworthy components we had before. It’s time to apply the old lessons and to build the new ones.